
Clustering using Genetic Algorithm
13 Dec 2015Introduction
This post is in continuation to one of my earlier post Image Segmentation using K-Means Clustering. This post intends to demonstrate an algorithm which tries to resolve the drawbacks of K-Means Clustering by inducing parallelism in computation. For this project I have referred Genetic Algorithm-based Clustering technique research paper by Ujjwal Maulik and Sanghamitra Bandyopadhyay.
Frequently used Notations
| Notation | Description |
|---|---|
| n_samples | Number of samples in dataset |
| n_features | Dimension of a sample |
| n_clusters | Number of clusters into which image is to be segmented |
Genetic Algorithm
Genetic Algorithms are randomized search and optimization techniques guided by the principles of evoluion and naural genetics, having a large amout of implicit parallelism. These perform search in complex, large and multimodal landscapes, and provide near optimal-solutions for objective or fitness function of an optimization problem. These have wide applications in the field of pattern recognition such as GA based supervised and unsupervised classifiers.
We will use Genetic Algorithm for clustering data. Several clusering techniques are available in the literature. One of the widely used algorithm is K-Means which we have already discussed in an earlier post. K-Means algorithm work by optimizing the distance criterion either by minimizing the within cluster spread or by maximizing the inter-cluster seperation. Like in K-Means, we will again use within cluster spread as optimizing criterion. However, unlike K-Means the proposed technique can provide good results irrespective of the starting configuration and does not get stuck in local optimum.
-
Population Initialization
-
The first step is to randomly initialize P chromosomes where each chromosome is composed of K cluster centers similar to K-Means clustering.
-
Input data dimension - n_samples x n_features
-
Popuation Size - P x (n_clusters * n_features) where each row of Population corresponds to a chromosome
-
Cluster Centers of best chromosome dimension - n_clusters x n_features
-
-
Fitness Computation
-
Fitness computation is done in two phases similar to K-Means clustering. In first phase dist matrix is populated with distance of all the cluster centers from the chromosome under consideration. Then, each data point is assigned a cluster center whose distance from this data point is least and is stored in a lablels vector.
-
In the second phase, the cluster centers encoded in the current chromosome are replaced by mean of the data points assigned to the respective cluster center. After this a clustering metric is computed which is equal to the sum of distances of data points from their respective cluster centers. Fitness is defined as the inverse of this clustering metric. Thus the maximization of fitness function will lead to minimization of clustering metric. This is repeated for all the chromosomes present in the population.
-
dist dimension - n_samples x n_clusters
-
labels of best chromosome dimension - n_samples x 1
-
fitness dimension - P x 1
-
Mathematically, this operation can be represented as:
-
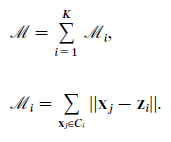
-
Selection
-
In this step, a fixed number of fittest chromosomes are selected to go into the mating pool for further genetic operations. Rest of the chromosomes are discarded from the population in order to maintain the initial population size.
-
Some of the selection stratergies are Roulette wheel selection and Tournament selection. Here, I have used Tournament selection according to which chromosomes are sorted according to their fitness values and the chromosomes with lower fitness values are discarded from the population.
-
-
Crossover
-
Crossover is a probabalistic process that exchanges information between two parent chromosomes for generating two child chromosomes. Here, I have used single point crossover with a fixed probability muc.
-
According to this two random chromosomes are selected and a random number(crossover point) is generated within 1 to l-1, where l is the length of chromosome. At the right of this crossover point, the genetic material between the two parent chromosomes is exchanged to generate two offsprings.
-
Number of Crossovers = 2 * muc * P
-
-
Mutation
-
Each chromosome undergoes mutation with a fixed probability mum. In this a random number delta is generated in the range [0, 1] with uniform distribution and a gene is selected for mutation at random.
-
Number of Mutations = mum * Number of crossover children
-
If the value of gene is v, after mutation it becomes
-
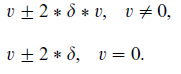
-
Termination
- Repeat Step 2 - Step 5 until one of the termination criteria has been met i.e. the difference between newly assigned labels and older labels is less than a particular tolerance value or until the maximum number of iterations have been reached.
Implementation
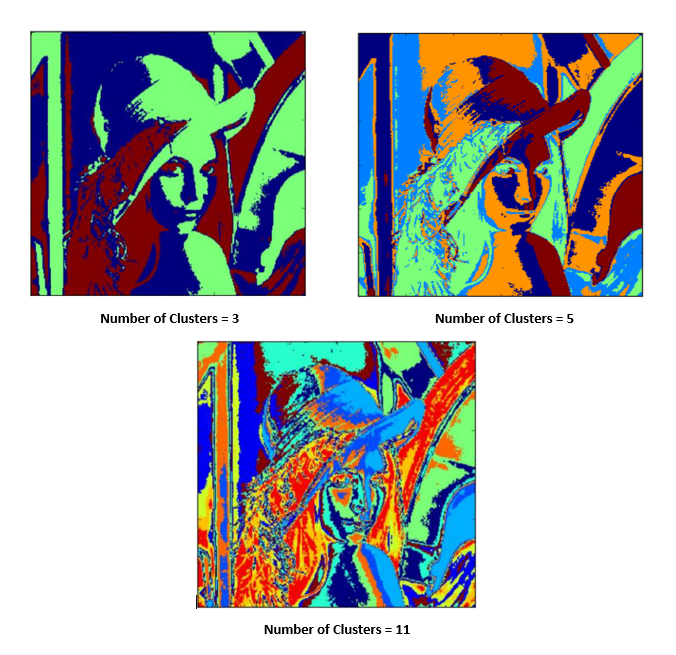
Results
Thanks!